Search Our Database
NovaGPU – Deploy GPU-Accelerated LLMs with Docker, Ollama & OpenWebUI on Ubuntu 24.04
NovaGPU – Deploy GPU-Accelerated LLMs with Docker, Ollama & OpenWebUI on Ubuntu 24.04
Introduction
This guide provides a step-by-step setup to deploy a GPU-accelerated environment in NovaCloud using NovaGPU on Ubuntu 22.04. It includes installation and configuration of NVIDIA drivers, Docker, NVIDIA Container Toolkit, Ollama (for running large language models), and OpenWebUI (a user-friendly front-end).
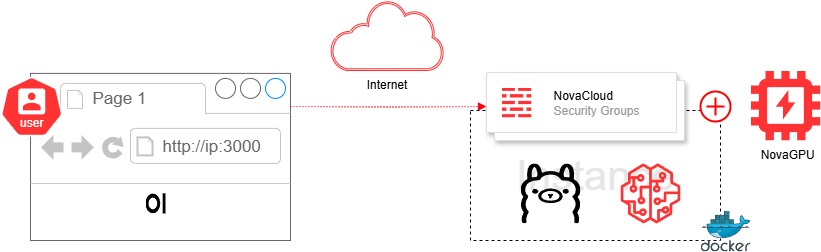
Prerequisites
- Access to customer portal https://portal.ipserverone.com
- Ubuntu 24.04 with an NVIDIA GPU – Launch NovaGPU Instances
- User with sudo access
-
Trusted IP for secure remote access – NovaCloud Security Group
Considerations
-
- Security: Open ports only to trusted IPs or protect with VPN. Setup the security group securely.
- Ollama: Avoid exposing 11434 openly, it should be protected.
- Storage: LLMs may consume 10–40GB per model, monitor disk usage. When setup for storage, start with 200GB if you plan to install a few model to test.
- GPU Usage: High usage for 13B+ models, monitor with nvidia-smi
Step-by-Step Guide
1. Update System and Install Basic Utilities
SSH to the serverInstall essential utilities for networking, downloads, and key management.
Ensures your system is up-to-date and has tools needed for subsequent installations.
sudo apt update sudo apt install net-tools
2. Install NVIDIA Driver
Provides required kernel drivers to utilize your NovaGPU.
sudo apt install -y nvidia-driver-575
Verify installation :
sudo nvidia-smi
Expected Output: GPU details with driver and CUDA version.
ubuntu@demo-gpu-a:~$ sudo nvidia-smi Fri Aug 1 07:10:28 2025 +-----------------------------------------------------------------------------------------+ | NVIDIA-SMI 575.64.03 Driver Version: 575.64.03 CUDA Version: 12.9 | |-----------------------------------------+------------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+========================+======================| | 0 NVIDIA GeForce RTX 3090 Off | 00000000:00:05.0 Off | N/A | | 30% 37C P0 112W / 350W | 1MiB / 24576MiB | 2% Default | | | | N/A | +-----------------------------------------+------------------------+----------------------+ +-----------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=========================================================================================| | No running processes found | +-----------------------------------------------------------------------------------------+
3. Install Docker
Container engine to run OpenWebUI and Ollama in isolated environments.
sudo apt install -y docker.io sudo systemctl enable docker sudo systemctl start docker sudo usermod -aG docker $USER
to verify docker is running, after testing, remove the hello-world container:
sudo docker run hello-world sudo docker container prune -f
This is the expected output
ubuntu@demo-gpu-a:~$ sudo docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
ubuntu@demo-gpu-a:~$ sudo docker run hello-world
Unable to find image 'hello-world:latest' locally
latest: Pulling from library/hello-world
e6590344b1a5: Pull complete
Digest: sha256:ec153840d1e635ac434fab5e377081f17e0e15afab27beb3f726c3265039cfff
Status: Downloaded newer image for hello-world:latest
Hello from Docker!
This message shows that your installation appears to be working correctly.
To generate this message, Docker took the following steps:
1. The Docker client contacted the Docker daemon.
2. The Docker daemon pulled the "hello-world" image from the Docker Hub.
(amd64)
3. The Docker daemon created a new container from that image which runs the
executable that produces the output you are currently reading.
4. The Docker daemon streamed that output to the Docker client, which sent it
to your terminal.
To try something more ambitious, you can run an Ubuntu container with:
$ docker run -it ubuntu bash
Share images, automate workflows, and more with a free Docker ID:
https://hub.docker.com/
For more examples and ideas, visit:
https://docs.docker.com/get-started/
ubuntu@demo-gpu-a:~$ sudo docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
9dfe1223fc72 hello-world "/hello" 27 seconds ago Exited (0) 27 seconds ago gallant_bell
ubuntu@demo-gpu-a:~$ sudo docker container prune -f
Deleted Containers:
9dfe1223fc721804de703c0d9c8d0a84c0a2a0e6f557486738e458942f6eb0de
Total reclaimed space: 0B
4. Install NVIDIA Container Toolkit
Enables Docker to interface with GPU for CUDA support, install it by adding the GPG key.
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg && \ curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \ sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \ sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list sudo apt update sudo apt-get install -y nvidia-container-toolkit sudo nvidia-ctk runtime configure --runtime=docker sudo systemctl restart docker
5. Install Ollama
Easy interface to download and run local open-source LLMs.
curl -fsSL https://ollama.com/install.sh | sh
Expected Output
ubuntu@demo-gpu-a:~$ curl -fsSL https://ollama.com/install.sh | sh >>> Installing ollama to /usr/local >>> Downloading Linux amd64 bundle ######################################################################## 100.0% >>> Creating ollama user... >>> Adding ollama user to render group... >>> Adding ollama user to video group... >>> Adding current user to ollama group... >>> Creating ollama systemd service... >>> Enabling and starting ollama service... Created symlink /etc/systemd/system/default.target.wants/ollama.service → /etc/systemd/system/ollama.service. >>> NVIDIA GPU installed.
6. Discover and Load LLM Models
Browse more models at https://ollama.com/library
Examples:
- ollama run mistral-small:24b
- ollama run qwen2.5vl:7b
- ollama run deepseek-r1:32b
- ollama run gemma3n:e4b
- ollama run deepseek-r1:14b
Test running LLMs directly.
ollama list ollama pull llama3 ollama run llama3
Expected Output :
ubuntu@demo-gpu-a:~$ ollama list ollama pull llama3 ollama run llama3 NAME ID SIZE MODIFIED pulling manifest pulling 6a0746a1ec1a: 100% ▕███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 4.7 GB pulling 4fa551d4f938: 100% ▕███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 12 KB pulling 8ab4849b038c: 100% ▕███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 254 B pulling 577073ffcc6c: 100% ▕███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 110 B pulling 3f8eb4da87fa: 100% ▕███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 485 B verifying sha256 digest writing manifest success >>> helo Hello! It's nice to meet you. Is there something I can help you with, or would you like to chat? >>> Send a message (/? for help)
7. Configure Ollama Host Binding
Enables external/Docker access to Ollama’s API service.
sudo bash -c 'FILE=/etc/systemd/system/ollama.service && sed -i "/^\[Service\]/,/^\[/ s|^Environment=OLLAMA_HOST=.*|Environment=OLLAMA_HOST=0.0.0.0:11434|" $FILE && grep -q "Environment=OLLAMA_HOST=0.0.0.0:11434" $FILE || sed -i "/^\[Service\]/a Environment=OLLAMA_HOST=0.0.0.0:11434" $FILE && systemctl daemon-reload && systemctl restart ollama.service'
Check if the ollama services is running on all IP, with netstat
ubuntu@demo-gpu-a:~$ sudo netstat -tulnp | grep 11434 tcp6 0 0 :::11434 :::* LISTEN 28310/ollama
Or, validate Systemd Service Is Running Correctly
ubuntu@demo-gpu-a:~$ systemctl show ollama.service | grep Environment Environment=OLLAMA_HOST=0.0.0.0:11434 PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin SetLoginEnvironment=no
8. Install OpenWebUI with Dynamic Host IP Mapping
Dynamic Host IP Mapping for simplified testing
sudo docker run -d \
-p 3000:8080 \
--add-host=host.docker.internal:$(hostname -I | awk '{print $1}') \
-e OLLAMA_BASE_URL=http://host.docker.internal:11434 \
-v open-webui:/app/backend/data \
--name open-webui \
--restart always \
ghcr.io/open-webui/open-webui:cuda
Expected Output
ubuntu@demo-gpu-a:~$ docker run -d \
-p 3000:8080 \
--add-host=host.docker.internal:$(hostname -I | awk '{print $1}') \
-e OLLAMA_BASE_URL=http://host.docker.internal:11434 \
-v open-webui:/app/backend/data \
--name open-webui \
--restart always \
ghcr.io/open-webui/open-webui:cuda
docker: permission denied while trying to connect to the Docker daemon socket at unix:///var/run/docker.sock: Head "http://%2Fvar%2Frun%2Fdocker.sock/_ping": dial unix /var/run/docker.sock: connect: permission denied.
See 'docker run --help'.
ubuntu@demo-gpu-a:~$ sudo docker run -d -p 3000:8080 --add-host=host.docker.internal:$(hostname -I | awk '{print $1}') -e OLLAMA_BASE_URL=http://host.docker.internal:11434 -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:cuda
Unable to find image 'ghcr.io/open-webui/open-webui:cuda' locally
cuda: Pulling from open-webui/open-webui
59e22667830b: Pull complete
abd846fa1cdb: Pull complete
b7b61708209a: Pull complete
4085babbc570: Pull complete
e8b89e896e26: Pull complete
4f4fb700ef54: Pull complete
ceec4205462d: Pull complete
f638e74b0183: Pull complete
dc4364b7159f: Pull complete
f8e9388aad82: Pull complete
51e16d4b14cc: Pull complete
7c2c465fe259: Pull complete
adec6d2205cb: Pull complete
e93d987e2485: Pull complete
db82a9755433: Pull complete
Digest: sha256:985636e9f6a53c2e441cbcc2631a9469ff514557beb319eff780645e219ba7fe
Status: Downloaded newer image for ghcr.io/open-webui/open-webui:cuda
a7052fe56f1c88cd1df55a8524a75bf1707d5b7a15c8d1c439fe0887777a2f26
ubuntu@demo-gpu-a:~$ sudo docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
a7052fe56f1c ghcr.io/open-webui/open-webui:cuda "bash start.sh" About a minute ago Up About a minute (healthy) 0.0.0.0:3000->8080/tcp, [::]:3000->8080/tcp open-webui
9. Access OpenWebUI
With the public IP and security group rules in place, you can access your Open-WebUI by navigating to http://your_instance_ip:3000 via browser.
Screen is loading
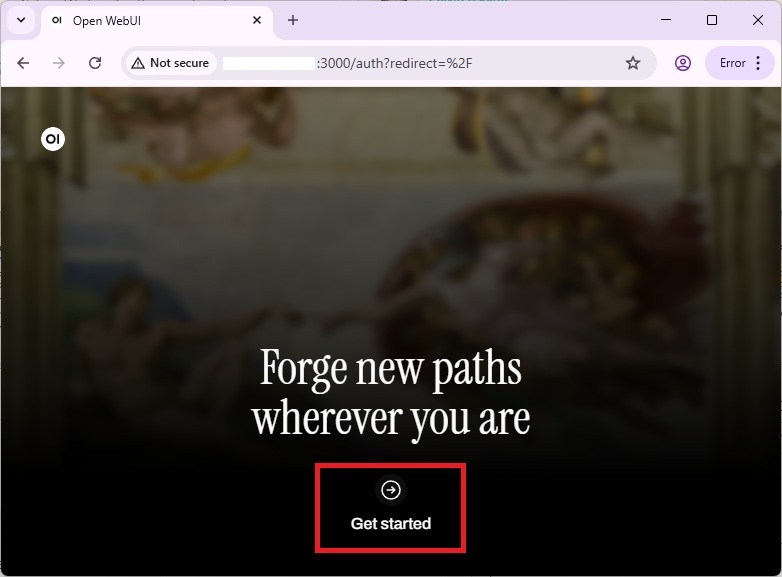
Click Get Started
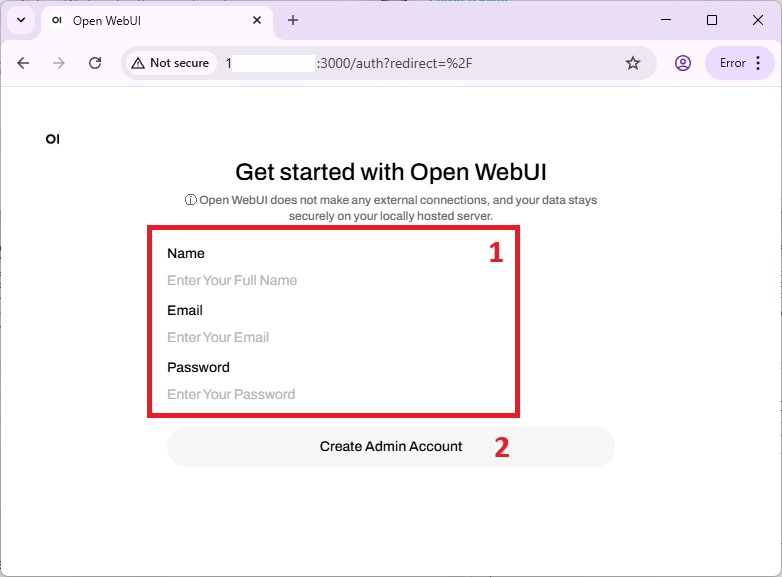
Create an admin login by providing Name, Email and Password as shown :
Model Usage: After creating account, click on the dropdown menu, to select your installed model and start interact with the model :
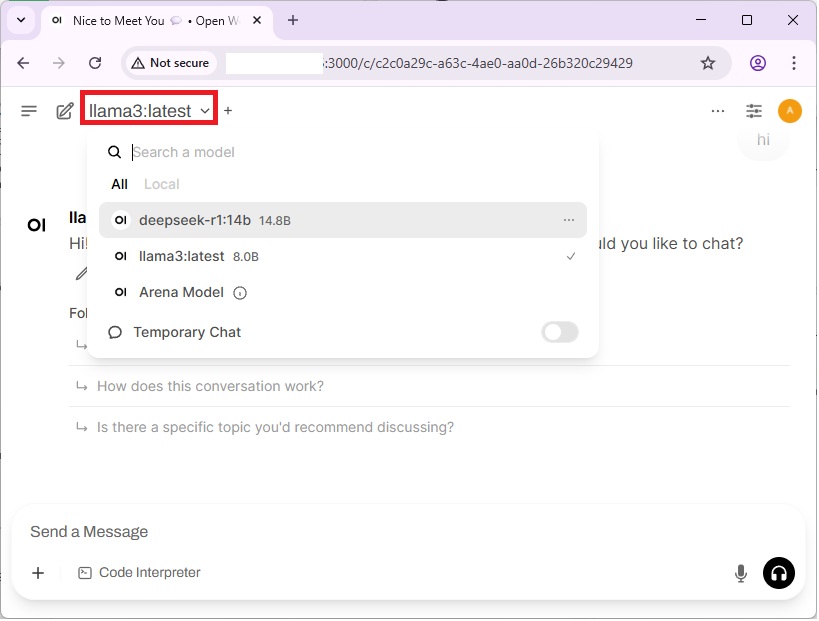
Now you can provide different prompts to the model to get response :
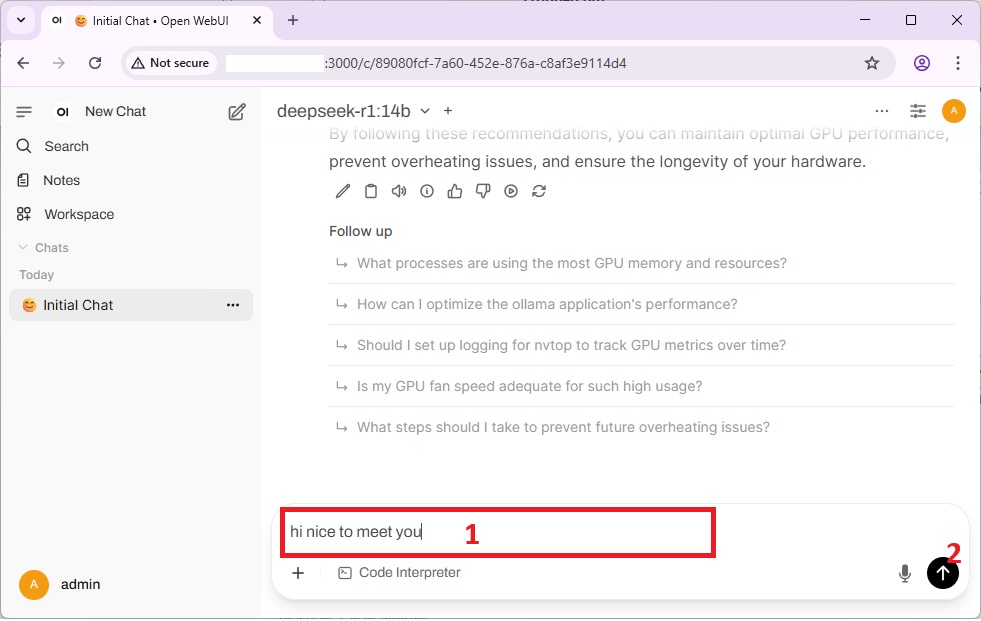
If you want to add more model, refer step 6.
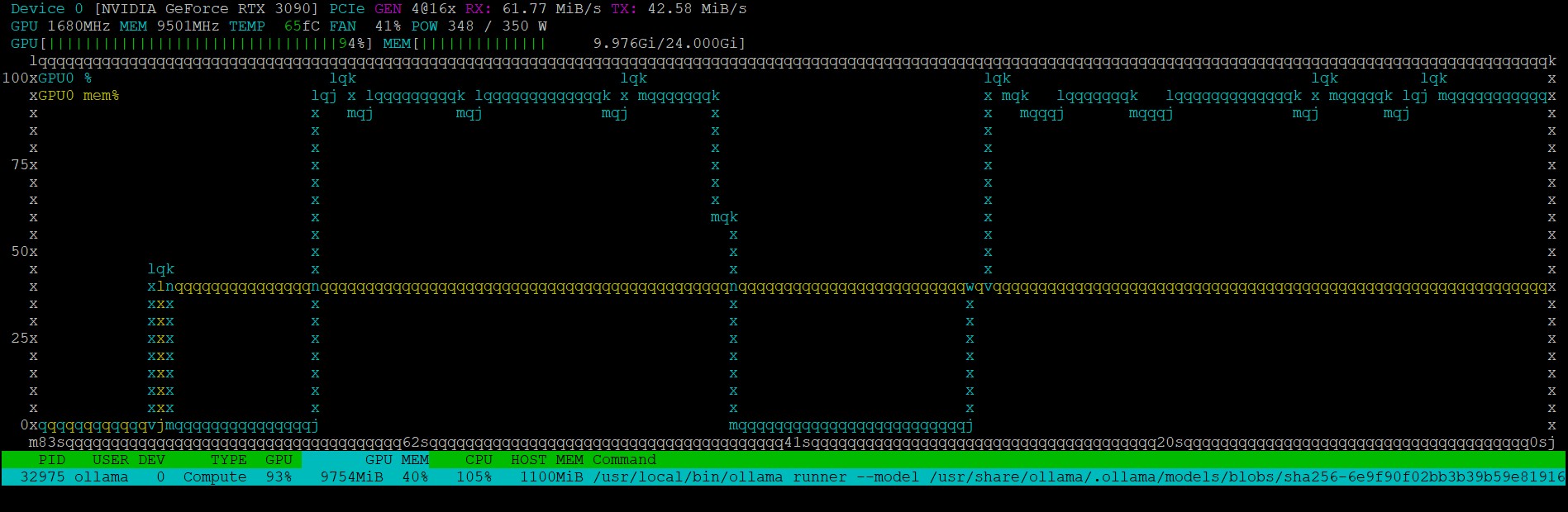
9. Monitor CPU and GPU
You can monitor the CPU and GPU usage with nvtop
sudo apt install nvtop nvtop
Conclusion
You’ve deployed a secure, GPU-enabled large language model (LLM) runtime along with a user-friendly web interface on a NovaGPU instance.
Need Help?
Reach out to our support team at support@ipserverone.com for assistance.